(web-api/get :dwarven-beard-waxes)
Chapter 9
The Sacred Art of Concurrent and Parallel Programming
If I were the lord of a manor and you were my heir, I would sit you down on your 13th name day and tell you, “The world of computing is changing, lass, and ye must be prepared for the new world of multi-core processors lest ye be trampled by it.
“Listen well: In recent years, CPU clock speeds have barely increased, but dual-core and quad-core computers have become common. The laws of physics are cruel and absolute, and they demand that increasing clock speed requires exponentially more power. The realm’s best engineers are unlikely to overcome this limitation anytime soon, if ever. Therefore, you can expect the trend of increasing cores on a single machine to continue—as will the expectation that you as a programmer will know how to make the most of modern hardware.
“Learning to program in this new paradigm will be fun and fascinating, verily. But beware: it is also fraught with peril. You must learn concurrent and parallel programming, which is the sacred art of structuring your application to safely manage multiple, simultaneously executing tasks.
“You begin your instruction in this art with an overview of concurrency and parallelism concepts. You’ll then study the three goblins that harry every practitioner: reference cells, mutual exclusion, and dwarven berserkers. And you’ll learn three tools that will aid you: futures, promises, and delays.”
And then I’d tap you on the shoulder with a keyboard, signaling that you were ready to begin.
Concurrency and Parallelism Concepts
Concurrent and parallel programming involves a lot of messy details at all levels of program execution, from the hardware to the operating system to programming language libraries to the code that springs from your heart and lands in your editor. But before you worry your head with any of those details, in this section I’ll walk through the high-level concepts that surround concurrency and parallelism.
Managing Multiple Tasks vs. Executing Tasks Simultaneously
Concurrency refers to managing more than one task at the same time. Task just means “something that needs to get done,” and it doesn’t imply anything regarding implementation in your hardware or software. We can illustrate concurrency with the song “Telephone” by Lady Gaga. Gaga sings,
I cannot text you with a drink in my hand, eh
Here, she’s explaining that she can only manage one task (drinking). She flat-out rejects the suggestion that she can manage more than one task. However, if she decided to process tasks concurrently, she would sing,
I will put down this drink to text you, then put my phone away and continue drinking, eh
In this hypothetical universe, Lady Gaga is managing two tasks: drinking and texting. However, she is not executing both tasks at the same time. Instead, she’s switching between the two, or interleaving. Note that, while interleaving, you don’t have to fully complete a task before switching: Gaga could type one word, put down her phone, pick up her drink and take a sip, and then switch back to her phone and type another word.
Parallelism refers to executing more than one task at the same time. If Madame Gaga were to execute her two tasks in parallel, she would sing,
I can text you with one hand while I use the other to drink, eh
Parallelism is a subclass of concurrency: before you execute multiple tasks simultaneously, you first have to manage multiple tasks.
Clojure has many features that allow you to achieve parallelism easily. While the Lady Gaga system achieves parallelism by simultaneously executing tasks on multiple hands, computer systems generally achieve parallelism by simultaneously executing tasks on multiple processors.
It’s important to distinguish parallelism from distribution. Distributed computing is a special version of parallel computing where the processors are in different computers and tasks are distributed to computers over a network. It’d be like Lady Gaga asking Beyoncé, “Please text this guy while I drink.” Although you can do distributed programming in Clojure with the aid of libraries, this book covers only parallel programming, and here I’ll use parallel to refer only to cohabiting processors. If you’re interested in distributed programming, check out Kyle Kingsbury’s Call Me Maybe series at https://aphyr.com/.
Blocking and Asynchronous Tasks
One of the major use cases for concurrent programming is for blocking operations. Blocking really just means waiting for an operation to finish. You’ll most often hear it used in relation to I/O operations, like reading a file or waiting for an HTTP request to finish. Let’s examine this using the concurrent Lady Gaga example.
If Lady Gaga texts her interlocutor and then stands there with her phone in her hand, staring at the screen for a response and not drinking, then you would say that the read next text message operation is blocking and that these tasks are executing synchronously.
If, instead, she tucks her phone away so she can drink until it alerts her by beeping or vibrating, then the read next text message task is not blocking and you would say she’s handling the task asynchronously.
Concurrent Programming and Parallel Programming
Concurrent programming and parallel programming refer to techniques for decomposing a task into subtasks that can execute in parallel and managing the risks that arise when your program executes more than one task at the same time. For the rest of the chapter, I’ll use the two terms interchangeably because the risks are pretty much the same for both.
To better understand those risks and how Clojure helps you avoid them, let’s examine how concurrency and parallelism are implemented in Clojure.
Clojure Implementation: JVM Threads
I’ve been using the term task in an abstract sense to refer to a series of related operations without regard for how a computer might implement the task concept. For example, texting is a task that consists of a series of related operations that are totally separate from the operations involved in pouring a drink into your face.
In Clojure, you can think of your normal, serial code as a sequence of tasks. You indicate that tasks can be performed concurrently by placing them on JVM threads.
What’s a Thread?
I’m glad you asked! A thread is a subprogram. A program can have many threads, and each thread executes its own set of instructions while enjoying shared access to the program’s state.

Thread management functionality can exist at multiple levels in a computer. For example, the operating system kernel typically provides system calls to create and manage threads. The JVM provides its own platform-independent thread management functionality, and since Clojure programs run in the JVM, they use JVM threads. You’ll learn more about the JVM in Chapter 12.
You can think of a thread as an actual, physical piece of thread that strings together a sequence of instructions. In my mind, the instructions are marshmallows, because marshmallows are delicious. The processor executes these instructions in order. I picture this as an alligator consuming the instructions, because alligators love marshmallows (true fact!). So executing a program looks like a bunch of marshmallows strung out on a line with an alligator traveling down the line and eating them one by one. Figure 9-1 shows this model for a single-core processor executing a single-threaded program.

Figure 9-1: Single-core processor executing a single-threaded program
A thread can spawn a new thread to execute tasks concurrently. In a single-processor system, the processor switches back and forth between the threads (interleaving). Here’s where potential concurrency issues get introduced. Although the processor executes the instructions on each thread in order, it makes no guarantees about when it will switch back and forth between threads.
Figure 9-2 shows an illustration of two threads, A and B, and a timeline of how their instructions could be executed. I’ve shaded the instructions on thread B to help distinguish them from the instructions on thread A.
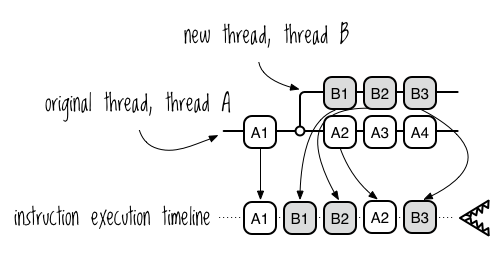
Single-core processor executing two threads
Note that this is just one possible order of instruction execution. The processor could also have executed the instructions in the order A1, A2, A3, B1, A4, B2, B3 for example. This makes the program nondeterministic. You can’t know beforehand what the result will be because you can’t know the execution order, and different execution orders can yield different results.
This example shows concurrent execution on a single processor through interleaving, whereas a multi-core system assigns a thread to each core, allowing the computer to execute more than one thread simultaneously. Each core executes its thread’s instructions in order, as shown in Figure 9-3.
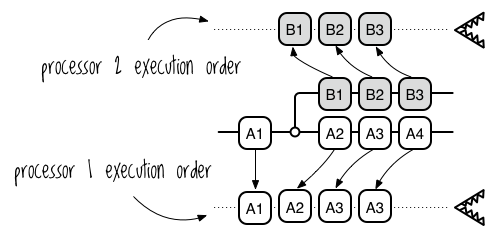
Two threads, two processors
As with interleaving on a single core, there are no guarantees for the overall execution order, so the program is nondeterministic. When you add a second thread to a program, it becomes nondeterministic, and this makes it possible for your program to fall prey to three kinds of problems.
The Three Goblins: Reference Cells, Mutual Exclusion, and Dwarven Berserkers
There are three central challenges in concurrent programming, also known as the The Three Concurrency Goblins. To see why these are scary, imagine that the program in the image in Figure 9-3 includes the pseudoinstructions in Table 9-1.
- Instructions for a Program with a Nondeterministic Outcome
| ID | Instruction |
|---|---|
| A1 |
WRITE X = 0
|
| A2 |
READ X
|
| A3 |
WRITE X = X + 1
|
| B1 |
READ X
|
| B2 |
WRITE X = X + 1
|
If the processor follows the order A1, A2, A3, B1, B2, then X will have a value of 2, as you’d expect. But if it follows the order A1, A2, B1, A3, B2, X’s value will be 1, as you can see in Figure 9-4.
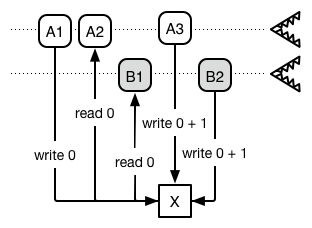
Two threads interacting with a reference cell
We’ll call this the reference cell problem (the first Concurrency Goblin). The reference cell problem occurs when two threads can read and write to the same location, and the value at the location depends on the order of the reads and writes.
The second Concurrency Goblin is mutual exclusion. Imagine two threads, each trying to write a spell to a file. Without any way to claim exclusive write access to the file, the spell will end up garbled because the write instructions will be interleaved. Consider the following two spells:
By the power invested in me
by the state of California,
I now pronounce you man and wife
Thunder, lightning, wind, and rain,
a delicious sandwich, I summon again
If you write these to a file without mutual exclusion, you could end up with this:
By the power invested in me
by Thunder, lightning, wind, and rain,
the state of California,
I now pronounce you a delicious man sandwich, and wife
I summon again
The third Concurrency Goblin is what I’ll call the dwarven berserker problem (aka deadlock). Imagine four berserkers sitting around a rough-hewn, circular wooden table comforting each other. “I know I’m distant toward my children, but I just don’t know how to communicate with them,” one growls. The rest sip their coffee and nod knowingly, care lines creasing their eye places.
Now, as everyone knows, the dwarven berserker ritual for ending a comforting coffee klatch is to pick up their “comfort sticks” (double-bladed war axes) and scratch each other’s backs. One war axe is placed between each pair of dwarves, as shown in Figure 9-5.
Their ritual proceeds thusly:
- Pick up the left war axe, when available.
- Pick up the right war axe, when available.
- Comfort your neighbor with vigorous swings of your “comfort sticks.”
- Release both war axes.
- Repeat.
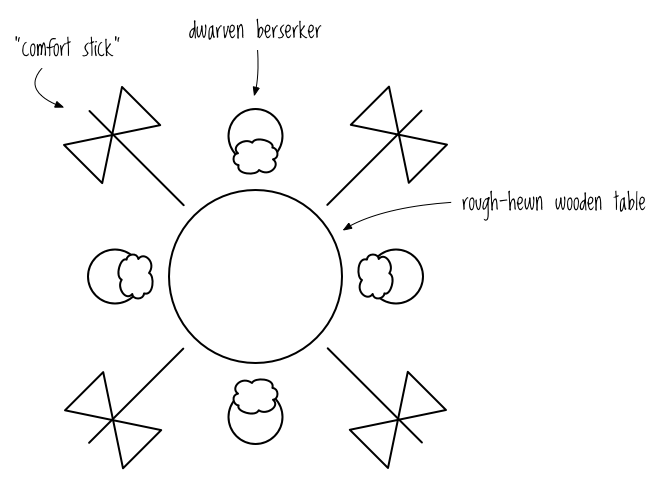
Dwarven berserkers at a comforting coffee klatch
Following this ritual, it’s entirely possible that all the dwarven berserkers will pick up their left comfort stick and then block indefinitely while waiting for the comfort stick to their right to become available, resulting in deadlock. (By the way, if you want to look into this phenomenon further, it’s usually referred to as the dining philosophers problem, but that’s a more boring scenario.) This book doesn’t discuss deadlock in much detail, but it’s good to know the concept and its terminology.
Concurrent programming has its goblins, but with the right tools, it’s manageable and even fun. Let’s start looking at the right tools.
Futures, Delays, and Promises
Futures, delays, and promises are easy, lightweight tools for concurrent programming. In this section, you’ll learn how each one works and how to use them together to defend against the reference cell Concurrency Goblin and the mutual exclusion Concurrency Goblin. You’ll discover that, although simple, these tools go a long way toward meeting your concurrency needs.
They do this by giving you more flexibility than is possible with serial code. When you write serial code, you bind together these three events:
- Task definition
- Task execution
- Requiring the task’s result
As an example, look at this hypothetical code, which defines a simple API call task:
As soon as Clojure encounters this task definition, it executes it. It also requires the result right now, blocking until the API call finishes. Part of learning concurrent programming is learning to identify when these chronological couplings aren’t necessary. Futures, delays, and promises allow you to separate task definition, task execution, and requiring the result. Onward!
Futures
In Clojure, you can use futures to define a task and place it on another thread without requiring the result immediately. You can create a future with the future macro. Try this in a REPL:
(future (Thread/sleep 4000)
(println "I'll print after 4 seconds"))
(println "I'll print immediately")
Thread/sleep tells the current thread to just sit on its bum and do nothing for the specified number of milliseconds. Normally, if you evaluated Thread/sleep in your REPL, you wouldn’t be able to evaluate any other statements until the REPL was done sleeping; the thread executing your REPL would be blocked. However, future creates a new thread and places each expression you pass it on the new thread, including Thread/sleep, allowing the REPL’s thread to continue, unblocked.
You can use futures to run tasks on a separate thread and then forget about them, but often you’ll want to use the result of the task. The future function returns a reference value that you can use to request the result. The reference is like the ticket that a dry cleaner gives you: at any time you can use it to request your clean dress, but if your dress isn’t clean yet, you’ll have to wait. Similarly, you can use the reference value to request a future’s result, but if the future isn’t done computing the result, you’ll have to wait.
Requesting a future’s result is called dereferencing the future, and you do it with either the deref function or the @ reader macro. A future’s result value is the value of the last expression evaluated in its body. A future’s body executes only once, and its value gets cached. Try the following:
(let [result (future (println "this prints once")
(+ 1 1))]
(println "deref: " (deref result))
(println "@: " @result))
; => "this prints once"
; => deref: 2
; => @: 2
Notice that the string "this prints once" indeed prints only once, even though you dereference the future twice. This shows that the future’s body ran only once and the result, 2, got cached.
Dereferencing a future will block if the future hasn’t finished running, like so:
(let [result (future (Thread/sleep 3000)
(+ 1 1))]
(println "The result is: " @result)
(println "It will be at least 3 seconds before I print"))
; => The result is: 2
; => It will be at least 3 seconds before I print
Sometimes you want to place a time limit on how long to wait for a future. To do that, you can pass deref a number of milliseconds to wait along with the value to return if the deref times out:
(deref (future (Thread/sleep 1000) 0) 10 5)
; => 5
This code tells deref to return the value 5 if the future doesn’t return a value within 10 milliseconds.
Finally, you can interrogate a future using realized? to see if it’s done running:
(realized? (future (Thread/sleep 1000)))
; => false
(let [f (future)]
@f
(realized? f))
; => true
Futures are a dead-simple way to sprinkle some concurrency on your program.
On their own, they give you the power to chuck tasks onto other threads, which can make your program more efficient. They also let your program behave more flexibly by giving you control over when a task’s result is required.
When you dereference a future, you indicate that the result is required right now and that evaluation should stop until the result is obtained. You’ll see how this can help you deal with the mutual exclusion problem in just a bit. Alternatively, you can ignore the result. For example, you can use futures to write to a log file asynchronously, in which case you don’t need to dereference the future to get any value back.
The flexibility that futures give you is very cool. Clojure also allows you to treat task definition and requiring the result independently with delays and promises.
Delays
Delays allow you to define a task without having to execute it or require the result immediately. You can create a delay using delay:
(def jackson-5-delay
(delay (let [message "Just call my name and I'll be there"]
(println "First deref:" message)
message)))
In this example, nothing is printed, because we haven’t yet asked the let form to be evaluated. You can evaluate the delay and get its result by dereferencing it or by using force. force behaves identically to deref in that it communicates more clearly that you’re causing a task to start as opposed to waiting for a task to finish:
(force jackson-5-delay)
; => First deref: Just call my name and I'll be there
; => "Just call my name and I'll be there"
Like futures, a delay is run only once and its result is cached. Subsequent dereferencing will return the Jackson 5 message without printing anything:
@jackson-5-delay
; => "Just call my name and I'll be there"
One way you can use a delay is to fire off a statement the first time one future out of a group of related futures finishes. For example, pretend your app uploads a set of headshots to a headshot-sharing site and notifies the owner as soon as the first one is up, as in the following:
(def gimli-headshots ["serious.jpg" "fun.jpg" "playful.jpg"])
(defn email-user
[email-address]
(println "Sending headshot notification to" email-address))
(defn upload-document
"Needs to be implemented"
[headshot]
true)
(let [notify (delay ➊(email-user "[email protected]"))]
(doseq [headshot gimli-headshots]
(future (upload-document headshot)
➋(force notify))))
In this example, you define a vector of headshots to upload (gimli-headshots) and two functions (email-user and upload-document) to pretend-perform the two operations. Then you use let to bind notify to a delay. The body of the delay, (email-user "[email protected]") ➊, isn’t evaluated when the delay is created. Instead, it gets evaluated the first time one of the futures created by the doseq form evaluates (force notify) ➋. Even though (force notify) will be evaluated three times, the delay body is evaluated only once. Gimli will be grateful to know when the first headshot is available so he can begin tweaking it and sharing it. He’ll also appreciate not being spammed, and you’ll appreciate not facing his dwarven wrath.
This technique can help protect you from the mutual exclusion Concurrency Goblin—the problem of making sure that only one thread can access a particular resource at a time. In this example, the delay guards the email server resource. Because the body of a delay is guaranteed to fire only once, you can be sure that you will never run into a situation where two threads send the same email. Of course, no thread will ever be able to use the delay to send an email again. That might be too drastic a constraint for most situations, but in cases like this example, it works perfectly.
Promises
Promises allow you to express that you expect a result without having to define the task that should produce it or when that task should run. You create promises using promise and deliver a result to them using deliver. You obtain the result by dereferencing:
(def my-promise (promise))
(deliver my-promise (+ 1 2))
@my-promise
; => 3
Here, you create a promise and then deliver a value to it. Finally, you obtain the value by dereferencing the promise. Dereferencing is how you express that you expect a result, and if you had tried to dereference my-promise without first delivering a value, the program would block until a promise was delivered, just like with futures and delays. You can only deliver a result to a promise once.
One use for promises is to find the first satisfactory element in a collection of data. Suppose, for example, that you’re gathering ingredients to make your parrot sound like James Earl Jones. Because James Earl Jones has the smoothest voice on earth, one of the ingredients is premium yak butter with a smoothness rating of 97 or greater. You have a budget of $100 for one pound.
You are a modern practitioner of the magico-ornithological arts, so rather than tediously navigating each yak butter retail site, you create a script to give you the URL of the first yak butter that meets your needs.
The following code defines some yak butter products, creates a function to mock up an API call, and creates another function to test whether a product is satisfactory:
(def yak-butter-international
{:store "Yak Butter International"
:price 90
:smoothness 90})
(def butter-than-nothing
{:store "Butter Than Nothing"
:price 150
:smoothness 83})
;; This is the butter that meets our requirements
(def baby-got-yak
{:store "Baby Got Yak"
:price 94
:smoothness 99})
(defn mock-api-call
[result]
(Thread/sleep 1000)
result)
(defn satisfactory?
"If the butter meets our criteria, return the butter, else return false"
[butter]
(and (<= (:price butter) 100)
(>= (:smoothness butter) 97)
butter))
The API call waits one second before returning a result to simulate the time it would take to perform an actual call.
To show how long it will take to check the sites synchronously, we’ll use some to apply the satisfactory? function to each element of the collection and return the first truthy result, or nil if there are none. When you check each site synchronously, it could take more than one second per site to obtain a result, as the following code shows:
(time (some (comp satisfactory? mock-api-call)
[yak-butter-international butter-than-nothing baby-got-yak]))
; => "Elapsed time: 3002.132 msecs"
; => {:store "Baby Got Yak", :smoothness 99, :price 94}
Here I’ve used comp to compose functions, and I’ve used time to print the time taken to evaluate a form. You can use a promise and futures to perform each check on a separate thread. If your computer has multiple cores, this could reduce the time it takes to about one second:
(time
(let [butter-promise (promise)]
(doseq [butter [yak-butter-international butter-than-nothing baby-got-yak]]
(future (if-let [satisfactory-butter (satisfactory? (mock-api-call butter))]
(deliver butter-promise satisfactory-butter))))
(println "And the winner is:" @butter-promise)))
; => "Elapsed time: 1002.652 msecs"
; => And the winner is: {:store Baby Got Yak, :smoothness 99, :price 94}
In this example, you first create a promise, butter-promise, and then create three futures with access to that promise. Each future’s task is to evaluate a yak butter site and to deliver the site’s data to the promise if it’s satisfactory. Finally, you dereference butter-promise, causing the program to block until the site data is delivered. This takes about one second instead of three because the site evaluations happen in parallel. By decoupling the requirement for a result from how the result is actually computed, you can perform multiple computations in parallel and save some time.
You can view this as a way to protect yourself from the reference cell Concurrency Goblin. Because promises can be written to only once, you prevent the kind of inconsistent state that arises from nondeterministic reads and writes.
You might be wondering what happens if none of the yak butter is satisfactory. If that happens, the dereference would block forever and tie up the thread. To avoid that, you can include a timeout:
(let [p (promise)]
(deref p 100 "timed out"))
This creates a promise, p, and tries to dereference it. The number 100 tells deref to wait 100 milliseconds, and if no value is available by then, to use the timeout value, "timed out".
The last detail I should mention is that you can also use promises to register callbacks, achieving the same functionality that you might be used to in JavaScript. JavaScript callbacks are a way of defining code that should execute asynchronously once some other code finishes. Here’s how to do it in Clojure:
(let [ferengi-wisdom-promise (promise)]
(future (println "Here's some Ferengi wisdom:" @ferengi-wisdom-promise))
(Thread/sleep 100)
(deliver ferengi-wisdom-promise "Whisper your way to success."))
; => Here's some Ferengi wisdom: Whisper your way to success.
This example creates a future that begins executing immediately. However, the future’s thread is blocking because it’s waiting for a value to be delivered to ferengi-wisdom-promise. After 100 milliseconds, you deliver the value and the println statement in the future runs.
Futures, delays, and promises are great, simple ways to manage concurrency in your application. In the next section, we’ll look at one more fun way to keep your concurrent applications under control.
Rolling Your Own Queue
So far you’ve looked at some simple ways to combine futures, delays, and promises to make your concurrent programs a little safer. In this section, you’ll use a macro to combine futures and promises in a slightly more complex manner. You might not necessarily ever use this code, but it’ll show the power of these modest tools a bit more. The macro will require you to hold runtime logic and macro expansion logic in your head at the same time to understand what’s going on; if you get stuck, just skip ahead.
One characteristic The Three Concurrency Goblins have in common is that they all involve tasks concurrently accessing a shared resource—a variable, a printer, a dwarven war axe—in an uncoordinated way. If you want to ensure that only one task will access a resource at a time, you can place the resource access portion of a task on a queue that’s executed serially. It’s kind of like making a cake: you and a friend can separately retrieve the ingredients (eggs, flour, eye of newt, what have you), but some steps you’ll have to perform serially. You have to prepare the batter before you put it in the oven. Figure 9-6 illustrates this strategy.

Dividing tasks into a serial portion and a concurrent portion lets you safely make your code more efficient.
To implement the queuing macro, you’ll pay homage to the British, because they invented queues. You’ll use a queue to ensure that the customary British greeting “Ello, gov’na! Pip pip! Cheerio!” is delivered in the correct order. This demonstration will involve an abundance of sleeping, so here’s a macro to do that more concisely:
(defmacro wait
"Sleep `timeout` seconds before evaluating body"
[timeout & body]
`(do (Thread/sleep ~timeout) ~@body))
All this code does is take whatever forms you give it and insert a call to Thread/sleep before them, all wrapped up in do.
The code in Listing 9-1 splits up tasks into a concurrent portion and a serialized portion:
(let [saying3 (promise)]
(future (deliver saying3 (wait 100 "Cheerio!")))
@(let [saying2 (promise)]
(future (deliver saying2 (wait 400 "Pip pip!")))
➊ @(let [saying1 (promise)]
(future (deliver saying1 (wait 200 "'Ello, gov'na!")))
(println @saying1)
saying1)
(println @saying2)
saying2)
(println @saying3)
saying3)
- 9-1. The expansion of an enqueue macro call
The overall strategy is to create a promise for each task (in this case, printing part of the greeting) to create a corresponding future that will deliver a concurrently computed value to the promise. This ensures that all of the futures are created before any of the promises are dereferenced, and it ensures that the serialized portions are executed in the correct order. The value of saying1 is printed first—"'Ello, gov'na!"—then the value of saying2, and finally saying3. Returning saying1 in a let block and dereferencing the let block at ➊ ensures that you’ll be completely finished with saying1 before the code moves on to do anything to saying2, and this pattern is repeated with saying2 and saying3.
It might seem silly to dereference the let block, but doing so lets you abstract this code with a macro. And you will definitely want to use a macro, because writing out code like the previous example would drive you mental (as the British would say). Ideally, the macro would work as shown in Listing 9-2:
(-> (enqueue ➊saying ➋(wait 200 "'Ello, gov'na!") ➌(println @saying))
➍(enqueue saying (wait 400 "Pip pip!") (println @saying))
(enqueue saying (wait 100 "Cheerio!") (println @saying)))
- This is how you’d use enqueue.
The macro lets you name the promise that gets created ➊, define how to derive the value to deliver that promise ➋, and define what to do with the promise ➌. The macro can also take another enqueue macro call as its first argument, which lets you thread it ➍. Listing 9-3 shows how you can define the enqueue macro. After defining enqueue, the code in Listing 9-2 will expand into the code in Listing 9-1, with all the nested let expressions:
(defmacro enqueue
➊ ([q concurrent-promise-name concurrent serialized]
➋ `(let [~concurrent-promise-name (promise)]
(future (deliver ~concurrent-promise-name ~concurrent))
➌ (deref ~q)
~serialized
~concurrent-promise-name))
➍ ([concurrent-promise-name concurrent serialized]
`(enqueue (future) ~concurrent-promise-name ~concurrent ~serialized)))
- enqueue’s implementation
Notice first that this macro has two arities in order to supply a default value. The first arity ➊ is where the real work is done. It has the parameter q, and the second arity does not. The second arity ➍ calls the first with value (future) supplied for q; you’ll see why in a minute. At ➋, the macro returns a form that creates a promise, delivers its value in a future, dereferences whatever form is supplied for q, evaluates the serialized code, and finally returns the promise. q will usually be a nested let expression returned by another call to enqueue, like in Listing 9-2. If no value is supplied for q, the macro supplies a future so that the deref at ➌ doesn’t cause an exception.
Now that we’ve written the enqueue macro, let’s try it out to see whether it reduces the execution time!
(time @(-> (enqueue saying (wait 200 "'Ello, gov'na!") (println @saying))
(enqueue saying (wait 400 "Pip pip!") (println @saying))
(enqueue saying (wait 100 "Cheerio!") (println @saying))))
; => 'Ello, gov'na!
; => Pip pip!
; => Cheerio!
; => "Elapsed time: 401.635 msecs"
Blimey! The greeting is delivered in the correct order, and you can see by the elapsed time that the “work” of sleeping was handled concurrently.
Summary
It’s important for programmers like you to learn concurrent and parallel programming techniques so you can design programs that run efficiently on modern hardware. Concurrency refers to a program’s ability to carry out more than one task, and in Clojure you achieve this by placing tasks on separate threads. Programs execute in parallel when a computer has more than one CPU, which allows more than one thread to be executed at the same time.
Concurrent programming refers to the techniques used to manage three concurrency risks: reference cells, mutual exclusion, and deadlock. Clojure gives you three basic tools that help you mitigate those risks: futures, delays, and promises. Each tool lets you decouple the three events of defining a task, executing a task, and requiring a task’s result. Futures let you define a task and execute it immediately, allowing you to require the result later or never. Futures also cache their results. Delays let you define a task that doesn’t get executed until later, and a delay’s result gets cached. Promises let you express that you require a result without having to know about the task that produces that result. You can only deliver a value to a promise once.
In the next chapter, you’ll explore the philosophical side of concurrent programming and learn more sophisticated tools for managing the risks.
Exercises
- Write a function that takes a string as an argument and searches for it on Bing and Google using the
slurpfunction. Your function should return the HTML of the first page returned by the search. - Update your function so it takes a second argument consisting of the search engines to use.
- Create a new function that takes a search term and search engines as arguments, and returns a vector of the URLs from the first page of search results from each search engine.
 The print book longs for you to own it
The print book longs for you to own it
 OMG what!? Another book!?
OMG what!? Another book!? Great mama of the bahamas! Learn about reducers!
Great mama of the bahamas! Learn about reducers!