class CuddleZombie
# attr_accessor is just a shorthand way for creating getters and
# setters for the listed instance variables
attr_accessor :cuddle_hunger_level, :percent_deteriorated
def initialize(cuddle_hunger_level = 1, percent_deteriorated = 0)
self.cuddle_hunger_level = cuddle_hunger_level
self.percent_deteriorated = percent_deteriorated
end
end
fred = CuddleZombie.new(2, 3)
fred.cuddle_hunger_level # => 2
fred.percent_deteriorated # => 3
fred.cuddle_hunger_level = 3
fred.cuddle_hunger_level # => 3
Chapter 10
Clojure Metaphysics: Atoms, Refs, Vars, and Cuddle Zombies
The Three Concurrency Goblins are all spawned from the same pit of evil: shared access to mutable state. You can see this in the reference cell discussion in Chapter 9. When two threads make uncoordinated changes to the reference cell, the result is unpredictable.
Rich Hickey designed Clojure to specifically address the problems that develop from shared access to mutable state. In fact, Clojure embodies a very clear conception of state that makes it inherently safer for concurrency than most popular programming languages. It’s safe all the way down to its meta-freakin-physics.
In this chapter, you’ll learn about Clojure’s underlying metaphysics, as compared to the metaphysics of typical object-oriented (OO) languages. Learning this philosophy will prepare you to handle Clojure’s remaining concurrency tools, the atom, ref, and var reference types. (Clojure has one additional reference type, agents, which this book doesn’t cover.) Each of these types enables you to safely perform state-modifying operations concurrently. You’ll also learn about easy ways to make your program more efficient without introducing state at all.
Metaphysics attempts to answer two basic questions in the broadest possible terms:
- What is there?
- What is it like?
To draw out the differences between Clojure and OO languages, I’ll explain two different ways of modeling a cuddle zombie. Unlike a regular zombie, a cuddle zombie does not want to devour your brains. It only wants to spoon you and maybe smell your neck. That makes its undead, shuffling, decaying state all the more tragic. How could you try to kill something that only wants love? Who’s the real monster here?
Object-Oriented Metaphysics
OO metaphysics treats the cuddle zombie as an object that exists in the world. The object has properties that may change over time, but it’s still treated as a single, constant object. If that seems like a totally obvious, uncontroversial approach to zombie metaphysics, you probably haven’t spent hours in an intro philosophy class arguing about what it means for a chair to exist and what really makes it a chair in the first place.
The tricky part is that the cuddle zombie is always changing. Its body slowly deteriorates. Its undying hunger for cuddles grows fiercer with time. In OO terms, we would say that the cuddle zombie is an object with mutable state and that its state is ever fluctuating. But no matter how much the zombie changes, we still identify it as the same zombie. Here’s how you might model and interact with a cuddle zombie in Ruby:
- 10-1. Modeling cuddle zombie behavior with Ruby
In this example, you create a cuddle zombie, fred, with two attributes: cuddle_hunger_level and percent_deteriorated. fred starts out with a cuddle_hunger_level of just 2, but you can change it to whatever you want and it’s still good ol’ Fred, the same cuddle zombie. In this case, you changed its cuddle_hunger_level to 3.

You can see that this object is just a fancy reference cell. It’s subject to the same nondeterministic results in a multithreaded environment. For example, if two threads try to increment Fred’s hunger level with something like fred.cuddle_hunger_level = fred.cuddle_hunger_level + 1, one of the increments could be lost, just like in the example with two threads writing to X in “The Three Goblins: Reference Cells, Mutual Exclusion, and Dwarven Berserkers” on page 193.
Even if you’re only performing reads on a separate thread, the program will still be nondeterministic. For example, suppose you’re conducting research on cuddle zombie behavior. You want to log a zombie’s hunger level whenever it reaches 50 percent deterioration, but you want to do this on another thread to increase performance, using code like that in Listing 10-1:
if fred.percent_deteriorated >= 50
Thread.new { database_logger.log(fred.cuddle_hunger_level) }
end
- This Ruby code isn’t safe for concurrent execution.
The problem is that another thread could change fred before the write actually takes place.
For example, Figure 10-1 shows two threads executing from top to bottom. In this situation, it would be correct to write 5 to the database, but 10 gets written instead.
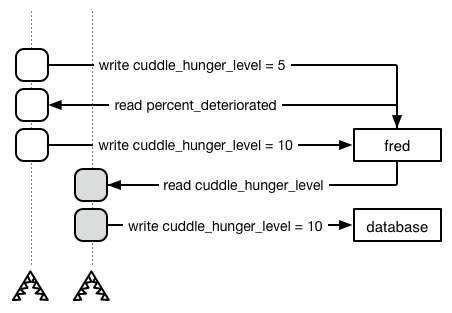
Figure 10-1: Logging inconsistent cuddle zombie data
This would be unfortunate. You don’t want your data to be inconsistent when you’re trying to recover from the cuddle zombie apocalypse. However, there’s no way to retain the state of an object at a specific moment in time.
Additionally, in order to change the cuddle_hunger_level and percent_deteriorated simultaneously, you must be extra careful. Otherwise, it’s possible for fred to be viewed in an inconsistent state, because another thread might read the fred object in between the two changes that you intend to be simultaneous, like so:
fred.cuddle_hunger_level = fred.cuddle_hunger_level + 1
# At this time, another thread could read fred's attributes and
# "perceive" fred in an inconsistent state unless you use a mutex
fred.percent_deteriorated = fred.percent_deteriorated + 1
This is another version of the mutual exclusion problem. In object-oriented programming (OOP), you can manually address this problem with a mutex, which ensures that only one thread can access a resource (in this case, the fred object) at a time for the duration of the mutex.
The fact that objects are never stable doesn’t stop us from treating them as the fundamental building blocks of programs. In fact, this is considered an advantage of OOP. It doesn’t matter how the state changes; you can still interact with a stable interface and everything will work as it should. This conforms to our intuitive sense of the world. A piece of wax is still the same piece of wax even if its properties change: if I change its color, melt it, and pour it on the face of my enemy, I’d still think of it as the same wax object I started with.
Also, in OOP, objects do things. They act on each other, changing state as the program runs. Again, this conforms to our intuitive sense of the world: change is the result of objects acting on each other. A Person object pushes on a Door object and enters a House object.
Clojure Metaphysics
In Clojure metaphysics, we would say that we never encounter the same cuddle zombie twice. The cuddle zombie is not a discrete thing that exists in the world independent of its mutations: it’s actually a succession of values.
The term value is used often by Clojurists, and its specific meaning might differ from what you’re used to. Values are atomic in the sense that they form a single irreducible unit or component in a larger system; they’re indivisible, unchanging, stable entities. Numbers are values: it wouldn’t make sense for the number 15 to mutate into another number. When you add or subtract from 15, you don’t change the number 15; you just wind up with a different number. Clojure’s data structures are also values because they’re immutable. When you use assoc on a map, you don’t modify the original map; instead, you derive a new map.
So a value doesn’t change, but you can apply a process to a value to produce a new value. For example, say we start with a value F1, and then we apply the Cuddle Zombie process to F1 to produce the value F2. The process then gets applied to the value F2 to produce the value F3, and so on.
This leads to a different conception of identity. Instead of understanding identity as inherent to a changing object, as in OO metaphysics, Clojure metaphysics construes identity as something we humans impose on a succession of unchanging values produced by a process over time. We use names to designate identities. The name Fred is a handy way to refer to a series of individual states F1, F2, F3, and so on. From this viewpoint, there’s no such thing as mutable state. Instead, state means the value of an identity at a point in time.
Rich Hickey has used the analogy of phone numbers to explain state. Alan’s phone number has changed 10 times, but we will always call these numbers by the same name, Alan’s phone number. Alan’s phone number five years ago is a different value than Alan’s phone number today, and both are two states of Alan’s phone number identity.
This makes sense when you consider that in your programs you are dealing with information about the world. Rather than saying that information has changed, you would say you’ve received new information. At 12:00 pm on Friday, Fred the Cuddle Zombie was in a state of 50 percent decay. At 1:00 pm, he was 60 percent decayed. These are both facts that you can process, and the introduction of a new fact does not invalidate a previous fact. Even though Fred’s decay increased from 50 percent to 60 percent, it’s still true that at 12:00 pm he was in a state of 50 percent decay.
Figure 10-2 shows how you might visualize values, process, identity, and state.
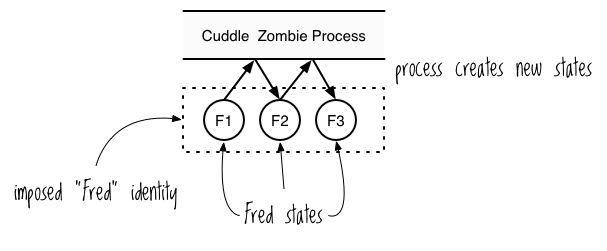
Figure 10-2: Values, process, identity, and state
These values don’t act on each other, and they can’t be changed. They can’t do anything. Change only occurs when a) a process generates a new value and b) we choose to associate the identity with the new value.
To handle this sort of change, Clojure uses reference types. Reference types let you manage identities in Clojure. Using them, you can name an identity and retrieve its state. Let’s look at the simplest of these, the atom.
Atoms
Clojure’s atom reference type allows you to endow a succession of related values with an identity. Here’s how you create one:
(def fred (atom {:cuddle-hunger-level 0
:percent-deteriorated 0}))
This creates a new atom and binds it to the name fred. This atom refers to the value {:cuddle-hunger-level 0 :percent-deteriorated 0}, and you would say that that’s its current state.
To get an atom’s current state, you dereference it. Here’s Fred’s current state:
@fred
; => {:cuddle-hunger-level 0, :percent-deteriorated 0}
Unlike futures, delays, and promises, dereferencing an atom (or any other reference type) will never block. When you dereference futures, delays, and promises, it’s like you’re saying “I need a value now, and I will wait until I get it,” so it makes sense that the operation would block. However, when you dereference a reference type, it’s like you’re saying “give me the value I’m currently referring to,” so it makes sense that the operation doesn’t block, because it doesn’t have to wait for anything.
In the Ruby example in Listing 10-1, we saw how object data could change while you try to log it on a separate thread. There’s no danger of that happening when using atoms to manage state, because each state is immutable. Here’s how you could log a zombie’s state with println:
(let [zombie-state @fred]
(if (>= (:percent-deteriorated zombie-state) 50)
(future (println (:cuddle-hunger-level zombie-state)))))
The problem with the Ruby example in Listing 10-1 was that it took two steps to read the zombie’s two attributes, and some other thread could have changed those attributes in between the two steps. However, by using atoms to refer to immutable data structures, you only have to perform one read, and the data structure returned won’t get altered by another thread.
To update the atom so that it refers to a new state, you use swap!. This might seem contradictory, because I said that atomic values are unchanging. Indeed, they are! But now we’re working with the atom reference type, a construct that refers to atomic values. The atomic values don’t change, but the reference type can be updated and assigned a new value.
swap! receives an atom and a function as arguments. It applies the function to the atom’s current state to produce a new value, and then it updates the atom to refer to this new value. The new value is also returned. Here’s how you might increase Fred’s cuddle hunger level by one:
(swap! fred
(fn [current-state]
(merge-with + current-state {:cuddle-hunger-level 1})))
; => {:cuddle-hunger-level 1, :percent-deteriorated 0}
Dereferencing fred will return the new state:
@fred
; => {:cuddle-hunger-level 1, :percent-deteriorated 0}
Unlike Ruby, it’s not possible for fred to be in an inconsistent state, because you can update the hunger level and deterioration percentage at the same time, like this:
(swap! fred
(fn [current-state]
(merge-with + current-state {:cuddle-hunger-level 1
:percent-deteriorated 1})))
; => {:cuddle-hunger-level 2, :percent-deteriorated 1}
This code passes swap! a function that takes only one argument, current-state. You can also pass swap! a function that takes multiple arguments. For example, you could create a function that takes two arguments, a zombie state and the amount by which to increase its cuddle hunger level:
(defn increase-cuddle-hunger-level
[zombie-state increase-by]
(merge-with + zombie-state {:cuddle-hunger-level increase-by}))
Let’s test increase-cuddle-hunger-level out real quick on a zombie state.
(increase-cuddle-hunger-level @fred 10)
; => {:cuddle-hunger-level 12, :percent-deteriorated 1}
Note that this code doesn’t actually update fred, because we’re not using swap! We’re just making a normal function call to increase-cuddle-hunger-level, which returns a result.
Now call swap! with the additional arguments, and @fred will be updated, like this:
(swap! fred increase-cuddle-hunger-level 10)
; => {:cuddle-hunger-level 12, :percent-deteriorated 1}
@fred
; => {:cuddle-hunger-level 12, :percent-deteriorated 1}
Or you could express the whole thing using Clojure’s built-in functions. The update-in function takes three arguments: a collection, a vector for identifying which value to update, and a function to update that value. It can also take additional arguments that get passed to the update function. Here are a couple of examples:
(update-in {:a {:b 3}} [:a :b] inc)
; => {:a {:b 4}}
(update-in {:a {:b 3}} [:a :b] + 10)
; => {:a {:b 13}}
In the first example, you’re updating the map {:a {:b 3}}. Clojure uses the vector [:a :b] to traverse the nested maps; :a yields the nested map {:b 3}, and :b yields the value 3. Clojure applies the inc function to 3 and returns a new map with 3 replaced by 4. The second example is similar. The only difference is that you’re using the addition function and you’re supplying 10 as an additional argument; Clojure ends up calling (+ 3 10).
Here’s how you can use the update-in function to change Fred’s state:
(swap! fred update-in [:cuddle-hunger-level] + 10)
; => {:cuddle-hunger-level 22, :percent-deteriorated 1}
By using atoms, you can retain past state. You can dereference an atom to retrieve State 1, and then update the atom, creating State 2, and still make use of State 1:
(let [num (atom 1)
s1 @num]
(swap! num inc)
(println "State 1:" s1)
(println "Current state:" @num))
; => State 1: 1
; => Current state: 2
This code creates an atom named num, retrieves its state, updates its state, and then prints its past state and its current state, showing that I wasn’t trying to trick you when I said you can retain past state, and therefore you can trust me with all manner of things—including your true name, which I promise to utter only to save you from mortal danger.
This is all interesting and fun, but what happens if two separate threads call (swap! fred increase-cuddle-hunger-level 1)? Is it possible for one of the increments to get lost the way it did in the Ruby example at Listing 10-1?
The answer is no! swap! implements compare-and-set semantics, meaning it does the following internally:
- It reads the current state of the atom.
- It then applies the update function to that state.
- Next, it checks whether the value it read in step 1 is identical to the atom’s current value.
- If it is, then
swap!updates the atom to refer to the result of step 2. -
If it isn’t, then
swap!retries, going through the process again with step 1.
This process ensures that no swaps will ever get lost.
One detail to note about swap! is that atom updates happen synchronously; they will block their thread. For example, if your update function calls Thread/sleep 1000 for some reason, the thread will block for at least a second while swap! completes.
Sometimes you’ll want to update an atom without checking its current value. For example, you might develop a serum that sets a cuddle zombie’s hunger level and deterioration back to zero. For those cases, you can use the reset! function:
(reset! fred {:cuddle-hunger-level 0
:percent-deteriorated 0})
And that covers all the core functionality of atoms! To recap: atoms implement Clojure’s concept of state. They allow you to endow a series of immutable values with an identity. They offer a solution to the reference cell and mutual exclusion problems through their compare-and-set semantics. They also allow you to work with past states without fear of them mutating in place.
In addition to these core features, atoms also share two features with the other reference types. You can attach both watches and validators to atoms. Let’s look at those now.
Watches and Validators
Watches allow you to be super creepy and check in on your reference types’ every move. Validators allow you to be super controlling and restrict what states are allowable. Both watches and validators are plain ol’ functions.
Watches
A watch is a function that takes four arguments: a key, the reference being watched, its previous state, and its new state. You can register any number of watches with a reference type.
Let’s say that a zombie’s shuffle speed (measured in shuffles per hour, or SPH) is dependent on its hunger level and deterioration. Here’s how you’d calculate it, multiplying the cuddle hunger level by how whole it is:
(defn shuffle-speed
[zombie]
(* (:cuddle-hunger-level zombie)
(- 100 (:percent-deteriorated zombie))))
Let’s also say that you want to be alerted whenever a zombie’s shuffle speed reaches the dangerous level of 5,000 SPH. Otherwise, you want to be told that everything’s okay. Here’s a watch function you could use to print a warning message if the SPH is above 5,000 and print an all’s-well message otherwise:
(defn shuffle-alert
[key watched old-state new-state]
(let [sph (shuffle-speed new-state)]
(if (> sph 5000)
(do
(println "Run, you fool!")
(println "The zombie's SPH is now " sph)
(println "This message brought to your courtesy of " key))
(do
(println "All's well with " key)
(println "Cuddle hunger: " (:cuddle-hunger-level new-state))
(println "Percent deteriorated: " (:percent-deteriorated new-state))
(println "SPH: " sph)))))
Watch functions take four arguments: a key that you can use for reporting, the atom being watched, the state of the atom before its update, and the state of the atom after its update. This watch function calculates the shuffle speed of the new state and prints a warning message if it’s too high and an all’s-well message when the shuffle speed is safe, as mentioned above. In both sets of messages, the key is used to let you know the source of the message.
You can attach this function to fred with add-watch. The general form of add-watch is (add-watch ref key watch-fn). In this example, we’re resetting fred’s state, adding the shuffle-alert watch function, and then updating fred’s state a couple of times to trigger shuffle-alert:
(reset! fred {:cuddle-hunger-level 22
:percent-deteriorated 2})
(add-watch fred :fred-shuffle-alert shuffle-alert)
(swap! fred update-in [:percent-deteriorated] + 1)
; => All's well with :fred-shuffle-alert
; => Cuddle hunger: 22
; => Percent deteriorated: 3
; => SPH: 2134
(swap! fred update-in [:cuddle-hunger-level] + 30)
; => Run, you fool!
; => The zombie's SPH is now 5044
; => This message brought to your courtesy of :fred-shuffle-alert
This example watch function didn’t use watched or old-state, but they’re there for you if the need arises. Now let’s cover validators.
Validators
Validators let you specify what states are allowable for a reference. For example, here’s a validator that you could use to ensure that a zombie’s :percent-deteriorated is between 0 and 100:
(defn percent-deteriorated-validator
[{:keys [percent-deteriorated]}]
(and (>= percent-deteriorated 0)
(<= percent-deteriorated 100)))
As you can see, the validator takes only one argument. When you add a validator to a reference, the reference is modified so that, whenever it’s updated, it will call this validator with the value returned from the update function as its argument. If the validator fails by returning false or throwing an exception, the reference won’t change to point to the new value.
You can attach a validator during atom creation:
(def bobby
(atom
{:cuddle-hunger-level 0 :percent-deteriorated 0}
:validator percent-deteriorated-validator))
(swap! bobby update-in [:percent-deteriorated] + 200)
; This throws "Invalid reference state"
In this example, percent-deteriorated-validator returned false and the atom update failed.
You can throw an exception to get a more descriptive error message:
(defn percent-deteriorated-validator
[{:keys [percent-deteriorated]}]
(or (and (>= percent-deteriorated 0)
(<= percent-deteriorated 100))
(throw (IllegalStateException. "That's not mathy!"))))
(def bobby
(atom
{:cuddle-hunger-level 0 :percent-deteriorated 0}
:validator percent-deteriorated-validator))
(swap! bobby update-in [:percent-deteriorated] + 200)
; This throws "IllegalStateException: That's not mathy!"
Pretty great! Now let’s look at refs.

Atoms are ideal for managing the state of independent identities. Sometimes, though, we need to express that an event should update the state of more than one identity simultaneously. Refs are the perfect tool for this scenario.
A classic example of this is recording sock gnome transactions. As we all know, sock gnomes take a single sock from every clothes dryer around the world. They use these socks to incubate their young. In return for this “gift,” sock gnomes protect your home from El Chupacabra. If you haven’t been visited by El Chupacabra lately, you have sock gnomes to thank.
To model sock transfers, we need to express that a dryer has lost a sock and a gnome has gained a sock simultaneously. One moment the sock belongs to the dryer; the next it belongs to the gnome. The sock should never appear to belong to both the dryer and the gnome, nor should it appear to belong to neither.
Modeling Sock Transfers
You can model this sock transfer with refs. Refs allow you to update the state of multiple identities using transaction semantics. These transactions have three features:
- They are atomic, meaning that all refs are updated or none of them are.
- They are consistent, meaning that the refs always appear to have valid states. A sock will always belong to a dryer or a gnome, but never both or neither.
- They are isolated, meaning that transactions behave as if they executed serially; if two threads are simultaneously running transactions that alter the same ref, one transaction will retry. This is similar to the compare-and-set semantics of atoms.
You might recognize these as the A, C, and I in the ACID properties of database transactions. You can think of refs as giving you the same concurrency safety as database transactions, only with in-memory data.
Clojure uses software transactional memory (STM) to implement this behavior. STM is very cool, but when you’re starting with Clojure, you don’t need to know much about it; you just need to know how to use it, which is what this section shows you.
Let’s start transferring some socks! First, you’ll need to code up some sock- and gnome-creation technology. The following code defines some sock varieties, then defines a couple of helper functions: sock-count will be used to help keep track of how many of each kind of sock belongs to either a gnome or a dryer, and generate-sock-gnome creates a fresh, sockless gnome:
(def sock-varieties
#{"darned" "argyle" "wool" "horsehair" "mulleted"
"passive-aggressive" "striped" "polka-dotted"
"athletic" "business" "power" "invisible" "gollumed"})
(defn sock-count
[sock-variety count]
{:variety sock-variety
:count count})
(defn generate-sock-gnome
"Create an initial sock gnome state with no socks"
[name]
{:name name
:socks #{}})
Now you can create your actual refs. The gnome will have 0 socks. The dryer, on the other hand, will have a set of sock pairs generated from the set of sock varieties. Here are our refs:
(def sock-gnome (ref (generate-sock-gnome "Barumpharumph")))
(def dryer (ref {:name "LG 1337"
:socks (set (map #(sock-count % 2) sock-varieties))}))
You can dereference refs just like you can dereference atoms. In this example, the order of your socks will probably be different because we’re using an unordered set:
(:socks @dryer)
; => #{{:variety "passive-aggressive", :count 2} {:variety "power", :count 2}
{:variety "athletic", :count 2} {:variety "business", :count 2}
{:variety "argyle", :count 2} {:variety "horsehair", :count 2}
{:variety "gollumed", :count 2} {:variety "darned", :count 2}
{:variety "polka-dotted", :count 2} {:variety "wool", :count 2}
{:variety "mulleted", :count 2} {:variety "striped", :count 2}
{:variety "invisible", :count 2}}
Now everything’s in place to perform the transfer. We’ll want to modify the sock-gnome ref to show that it has gained a sock and modify the dryer ref to show that it’s lost a sock. You modify refs using alter, and you must use alter within a transaction. dosync initiates a transaction and defines its extent; you put all transaction operations in its body. Here we use these tools to define a steal-sock function, and then call it on our two refs:
(defn steal-sock
[gnome dryer]
(dosync
(when-let [pair (some #(if (= (:count %) 2) %) (:socks @dryer))]
(let [updated-count (sock-count (:variety pair) 1)]
(alter gnome update-in [:socks] conj updated-count)
(alter dryer update-in [:socks] disj pair)
(alter dryer update-in [:socks] conj updated-count)))))
(steal-sock sock-gnome dryer)
(:socks @sock-gnome)
; => #{{:variety "passive-aggressive", :count 1}}
Now the gnome has one passive-aggressive sock, and the dryer has one less (your gnome may have stolen a different sock because the socks are stored in an unordered set). Let’s make sure all passive-aggressive socks are accounted for:
(defn similar-socks
[target-sock sock-set]
(filter #(= (:variety %) (:variety target-sock)) sock-set))
(similar-socks (first (:socks @sock-gnome)) (:socks @dryer))
; => ({:variety "passive-aggressive", :count 1})
There are a couple of details to note here: when you alter a ref, the change isn’t immediately visible outside of the current transaction. This is what lets you call alter on the dryer twice within a transaction without worrying about whether dryer will be read in an inconsistent state. Similarly, if you alter a ref and then deref it within the same transaction, the deref will return the new state.
Here’s an example to demonstrate this idea of in-transaction state:
(def counter (ref 0))
(future
(dosync
(alter counter inc)
(println @counter)
(Thread/sleep 500)
(alter counter inc)
(println @counter)))
(Thread/sleep 250)
(println @counter)
This prints 1, 0 , and 2, in that order. First, you create a ref, counter, which holds the number 0. Then you use future to create a new thread to run a transaction on. On the transaction thread, you increment the counter and print it, and the number 1 gets printed. Meanwhile, the main thread waits 250 milliseconds and prints the counter’s value, too. However, the value of counter on the main thread is still 0—the main thread is outside of the transaction and doesn’t have access to the transaction’s state. It’s like the transaction has its own private area for trying out changes to the state, and the rest of the world can’t know about them until the transaction is done. This is further illustrated in the transaction code: after it prints the first time, it increments the counter again from 1 to 2 and prints the result, 2.
The transaction will try to commit its changes only when it ends. The commit works similarly to the compare-and-set semantics of atoms. Each ref is checked to see whether it’s changed since you first tried to alter it. If any of the refs have changed, then none of the refs is updated and the transaction is retried. For example, if Transaction A and Transaction B are both attempted at the same time and events occur in the following order, Transaction A will be retried:
- Transaction A: alter gnome
- Transaction B: alter gnome
- Transaction B: alter dryer
- Transaction B: alter dryer
- Transaction B: commit—successfully updates gnome and dryer
- Transaction A: alter dryer
- Transaction A: alter dryer
- Transaction A: commit—fails because dryer and gnome have changed; retries.
And there you have it! Safe, easy, concurrent coordination of state changes. But that’s not all! Refs have one more trick up their suspiciously long sleeve: commute.
commute
commute allows you to update a ref’s state within a transaction, just like alter. However, its behavior at commit time is completely different. Here’s how alter behaves:
- Reach outside the transaction and read the ref’s current state.
- Compare the current state to the state the ref started with within the transaction.
- If the two differ, make the transaction retry.
- Otherwise, commit the altered ref state.
commute, on the other hand, behaves like this at commit time:
- Reach outside the transaction and read the ref’s current state.
- Run the
commutefunction again using the current state. - Commit the result.
As you can see, commute doesn’t ever force a transaction retry. This can help improve performance, but it’s important that you only use commute when you’re sure that it’s not possible for your refs to end up in an invalid state. Let’s look at examples of safe and unsafe uses of commute.
Here’s an example of a safe use. The sleep-print-update function returns the updated state but also sleeps the specified number of milliseconds so we can force transaction overlap. It prints the state that it’s attempting to update so we can gain insight into what’s going on:
(defn sleep-print-update
[sleep-time thread-name update-fn]
(fn [state]
(Thread/sleep sleep-time)
(println (str thread-name ": " state))
(update-fn state)))
(def counter (ref 0))
(future (dosync (commute counter (sleep-print-update 100 "Thread A" inc))))
(future (dosync (commute counter (sleep-print-update 150 "Thread B" inc))))
Here’s a timeline of what prints:
Thread A: 0 | 100ms
Thread B: 0 | 150ms
Thread A: 0 | 200ms
Thread B: 1 | 300ms
Notice that the last printed line reads Thread B: 1. That means that sleep-print-update receives 1 as the argument for state the second time it runs. That makes sense, because Thread A has committed its result by that point. If you dereference counter after the transactions run, you’ll see that the value is 2.
Now, here’s an example of unsafe commuting:
(def receiver-a (ref #{}))
(def receiver-b (ref #{}))
(def giver (ref #{1}))
(do (future (dosync (let [gift (first @giver)]
(Thread/sleep 10)
(commute receiver-a conj gift)
(commute giver disj gift))))
(future (dosync (let [gift (first @giver)]
(Thread/sleep 50)
(commute receiver-b conj gift)
(commute giver disj gift)))))
@receiver-a
; => #{1}
@receiver-b
; => #{1}
@giver
; => #{}
The 1 was given to both receiver-a and receiver-b, and you’ve ended up with two instances of 1, which isn’t valid for your program. What’s different about this example is that the functions that are applied, essentially #(conj % gift) and #(disj % gift), are derived from the state of giver. Once giver changes, the derived functions produce an invalid state, but commute doesn’t care that the resulting state is invalid and commits the result anyway. The lesson here is that although commute can help speed up your programs, you have to be judicious about when to use it.
Now you’re ready to start using refs safely and sanely. Refs have a few more nuances that I won’t cover here, but if you’re curious about them, you can research the ensure function and the phenomenon write skew.
On to the final reference type that this book covers: vars.
Vars
You’ve already learned a bit about vars in Chapter 6. To recap briefly, vars are associations between symbols and objects. You create new vars with def.
Although vars aren’t used to manage state in the same way as atoms and refs, they do have a couple of concurrency tricks: you can dynamically bind them, and you can alter their roots. Let’s look at dynamic binding first.
Dynamic Binding
When I first introduced def, I implored you to treat it as if it’s defining a constant. It turns out that vars are a bit more flexible than that: you can create a dynamic var whose binding can be changed. Dynamic vars can be useful for creating a global name that should refer to different values in different contexts.
Creating and Binding Dynamic Vars
First, create a dynamic var:
(def ^:dynamic *notification-address* "[email protected]")
Notice two important details here. First, you use ^:dynamic to signal to Clojure that a var is dynamic. Second, the var’s name is enclosed by asterisks. Lispers call these earmuffs, which is adorable. Clojure requires you to enclose the names of dynamic vars in earmuffs. This helps signal the var’s dynamicaltude to other programmers.
Unlike regular vars, you can temporarily change the value of dynamic vars by using binding:
(binding [*notification-address* "[email protected]"]
*notification-address*)
; => "[email protected]"
You can also stack bindings ( just like you can with let):
(binding [*notification-address* "[email protected]"]
(println *notification-address*)
(binding [*notification-address* "[email protected]"]
(println *notification-address*))
(println *notification-address*))
; => [email protected]
; => [email protected]
; => [email protected]
Now that you know how to dynamically bind a var, let’s look at a real-world application.
Dynamic Var Uses
Let’s say you have a function that sends a notification email. In this example, we’ll just return a string but pretend that the function actually sends the email:
(defn notify
[message]
(str "TO: " *notification-address* "\n"
"MESSAGE: " message))
(notify "I fell.")
; => "TO: [email protected]\nMESSAGE: I fell."
What if you want to test this function without spamming Dobby every time your specs run? Here comes binding to the rescue:
(binding [*notification-address* "[email protected]"]
(notify "test!"))
; => "TO: [email protected]\nMESSAGE: test!"
Of course, you could have just defined notify to take an email address as an argument. In fact, that’s often the right choice. Why would you want to use dynamic vars instead?
Dynamic vars are most often used to name a resource that one or more functions target. In this example, you can view the email address as a resource that you write to. In fact, Clojure comes with a ton of built-in dynamic vars for this purpose. *out*, for example, represents the standard output for print operations. In your program, you could re-bind *out* so that print statements write to a file, like so:
(binding [*out* (clojure.java.io/writer "print-output")]
(println "A man who carries a cat by the tail learns
something he can learn in no other way.
-- Mark Twain"))
(slurp "print-output")
; => A man who carries a cat by the tail learns
something he can learn in no other way.
-- Mark Twain
This is much less burdensome than passing an output destination to every invocation of println. Dynamic vars are a great way to specify a common resource while retaining the flexibility to change it on an ad hoc basis.
Dynamic vars are also used for configuration. For example, the built-in var *print-length* allows you to specify how many items in a collection Clojure should print:
(println ["Print" "all" "the" "things!"])
; => [Print all the things!]
(binding [*print-length* 1]
(println ["Print" "just" "one!"]))
; => [Print ...]

Finally, it’s possible to set! dynamic vars that have been bound. Whereas the examples you’ve seen so far allow you to convey information in to a function without having to pass in the information as an argument, set! allows you convey information out of a function without having to return it as an argument.
For example, let’s say you’re a telepath, but your mind-reading powers are a bit delayed. You can read people’s thoughts only after the moment when it would have been useful for you to know them. Don’t feel too bad, though; you’re still a telepath, which is awesome. Anyway, say you’re trying to cross a bridge guarded by a troll who will eat you if you don’t answer his riddle. His riddle is “What number between 1 and 2 am I thinking of?” In the event that the troll devours you, you can at least die knowing what the troll was actually thinking.
In this example, you create the dynamic var *troll-thought* to convey the troll’s thought out of the troll-riddle function:
(def ^:dynamic *troll-thought* nil)
(defn troll-riddle
[your-answer]
(let [number "man meat"]
➊ (when (thread-bound? #'*troll-thought*)
➋ (set! *troll-thought* number))
(if (= number your-answer)
"TROLL: You can cross the bridge!"
"TROLL: Time to eat you, succulent human!")))
(binding [*troll-thought* nil]
(println (troll-riddle 2))
(println "SUCCULENT HUMAN: Oooooh! The answer was" *troll-thought*))
; => TROLL: Time to eat you, succulent human!
; => SUCCULENT HUMAN: Oooooh! The answer was man meat
You use the thread-bound? function at ➊ to check that the var has been bound, and if it has, you set! *troll-thought* to the troll’s thought at ➋.
The var returns to its original value outside of binding:
*troll-thought*
; => nil
Notice that you have to pass #'*troll-thought* (including #'), not *troll-thought*, to the function thread-bound?. This is because thread-bound? takes the var itself as an argument, not the value it refers to.
Per-Thread Binding
One final point to note about binding: if you access a dynamically bound var from within a manually created thread, the var will evaluate to the original value. If you’re new to Clojure (and Java), this feature won’t be immediately relevant; you can probably skip this section and come back to it later.
Ironically, this binding behavior prevents us from easily creating a fun demonstration in the REPL, because the REPL binds *out*. It’s as if all the code you run in the REPL is implicitly wrapped in something like (binding [*out* repl-printer] your-code. If you create a new thread, *out* won’t be bound to the REPL printer.
The following example uses some basic Java interop. Even if it looks unfamiliar, the gist of the following code should be clear, and you’ll learn exactly what’s going on in Chapter 12.
This code prints output to the REPL:
(.write *out* "prints to repl")
; => prints to repl
The following code doesn’t print output to the REPL, because *out* is not bound to the REPL printer:
(.start (Thread. #(.write *out* "prints to standard out")))
You can work around this by using this goofy code:
(let [out *out*]
(.start
(Thread. #(binding [*out* out]
(.write *out* "prints to repl from thread")))))
Or you can use bound-fn, which carries all the current bindings to the new thread:
(.start (Thread. (bound-fn [] (.write *out* "prints to repl from thread"))))
The let binding captures *out* so we can then rebind it in the child thread, which is goofy as hell. The point is that bindings don’t get passed on to manually created threads. They do, however, get passed on to futures. This is called binding conveyance. Throughout this chapter, we’ve been printing from futures without any problem, for example.
That’s it for dynamic binding. Let’s turn our attention to the last var topic: altering var roots.
Altering the Var Root
When you create a new var, the initial value that you supply is its root:
(def power-source "hair")
In this example, "hair" is the root value of power-source. Clojure lets you permanently change this root value with the function alter-var-root:
(alter-var-root #'power-source (fn [_] "7-eleven parking lot"))
power-source
; => "7-eleven parking lot"
Just like when using swap! to update an atom or alter! to update a ref, you use alter-var-root along with a function to update the state of a var. In this case, the function is just returning a new string that bears no relation to the previous value, unlike the alter! examples where we used inc to derive a new number from the current number.
You’ll hardly ever want to do this. You especially don’t want to do this to perform simple variable assignment. If you did, you’d be going out of your way to create the binding as a mutable variable, which goes against Clojure’s philosophy; it’s best to use the functional programming techniques you learned in Chapter 5.
You can also temporarily alter a var’s root with with-redefs. This works similarly to binding except the alteration will appear in child threads. Here’s an example:
(with-redefs [*out* *out*]
(doto (Thread. #(println "with redefs allows me to show up in the REPL"))
.start
.join))
with-redefs can be used with any var, not just dynamic ones. Because it has has such far-reaching effects, you should only use it during testing. For example, you could use it to redefine a function that returns data from a network call, so that the function returns mock data without having to actually make a network request.
Now you know all about vars! Try not to hurt yourself or anyone you know with them.
Stateless Concurrency and Parallelism with pmap
So far, this chapter has focused on tools that are designed to mitigate the risks inherent in concurrent programming. You’ve learned about the dangers born of shared access to mutable state and how Clojure implements a reconceptualization of state that helps you write concurrent programs safely.
Often, though, you’ll want to concurrent-ify tasks that are completely independent of each other. There is no shared access to a mutable state; therefore, there are no risks to running the tasks concurrently and you don’t have to bother with using any of the tools I’ve just been blabbing on about.
As it turns out, Clojure makes it easy for you to write code for achieving stateless concurrency. In this section, you’ll learn about pmap, which gives you concurrency performance benefits virtually for free.
map is a perfect candidate for parallelization: when you use it, all you’re doing is deriving a new collection from an existing collection by applying a function to each element of the existing collection. There’s no need to maintain state; each function application is completely independent. Clojure makes it easy to perform a parallel map with pmap. With pmap, Clojure handles the running of each application of the mapping function on a separate thread.
To compare map and pmap, we need a lot of example data, and to generate this data, we’ll use the repeatedly function. This function takes another function as an argument and returns a lazy sequence. The elements of the lazy sequence are generated by calling the passed function, like this:
(defn always-1
[]
1)
(take 5 (repeatedly always-1))
; => (1 1 1 1 1)
Here’s how you’d create a lazy seq of random numbers between 0 and 9:
(take 5 (repeatedly (partial rand-int 10)))
; => (1 5 0 3 4)
Let’s use repeatedly to create example data that consists of a sequence of 3,000 random strings, each 7,000 characters long. We’ll compare map and pmap by using them to run clojure.string/lowercase on the orc-names sequence created here:
(def alphabet-length 26)
;; Vector of chars, A-Z
(def letters (mapv (comp str char (partial + 65)) (range alphabet-length)))
(defn random-string
"Returns a random string of specified length"
[length]
(apply str (take length (repeatedly #(rand-nth letters)))))
(defn random-string-list
[list-length string-length]
(doall (take list-length (repeatedly (partial random-string string-length)))))
(def orc-names (random-string-list 3000 7000))
Because map and pmap are lazy, we have to force them to be realized. We don’t want the result to be printed to the REPL, though, because that would take forever. The dorun function does just what we need: it realizes the sequence but returns nil:
(time (dorun (map clojure.string/lower-case orc-names)))
; => "Elapsed time: 270.182 msecs"
(time (dorun (pmap clojure.string/lower-case orc-names)))
; => "Elapsed time: 147.562 msecs"
The serial execution with map took about 1.8 times longer than pmap, and all you had to do was add one extra letter! Your performance may be even better, depending on the number of cores your computer has; this code was run on a dual-core machine.
You might be wondering why the parallel version didn’t take exactly half as long as the serial version. After all, it should take two cores only half as much time as a single core, shouldn’t it? The reason is that there’s always some overhead involved with creating and coordinating threads. Sometimes, in fact, the time taken by this overhead can dwarf the time of each function application, and pmap can actually take longer than map. Figure 10-3 shows how you can visualize this.
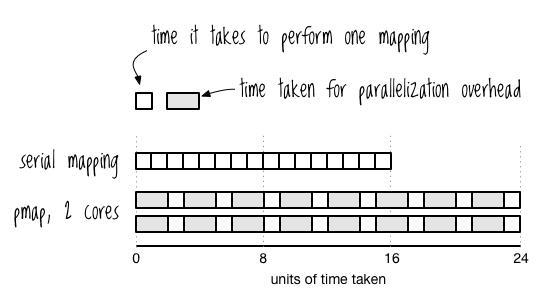
Figure 10-3: Parallelization overhead can dwarf task time, resulting in a performance decrease.
We can see this effect at work if we run a function on 20,000 abbreviated orc names, each 300 characters long:
(def orc-name-abbrevs (random-string-list 20000 300))
(time (dorun (map clojure.string/lower-case orc-name-abbrevs)))
; => "Elapsed time: 78.23 msecs"
(time (dorun (pmap clojure.string/lower-case orc-name-abbrevs)))
; => "Elapsed time: 124.727 msecs"
Now pmap actually takes 1.6 times longer.
The solution to this problem is to increase the grain size, or the amount of work done by each parallelized task. In this case, the task is to apply the mapping function to one element of the collection. Grain size isn’t measured in any standard unit, but you’d say that the grain size of pmap is one by default. Increasing the grain size to two would mean that you’re applying the mapping function to two elements instead of one, so the thread that the task is on is doing more work. Figure 10-4 shows how an increased grain size can improve performance.
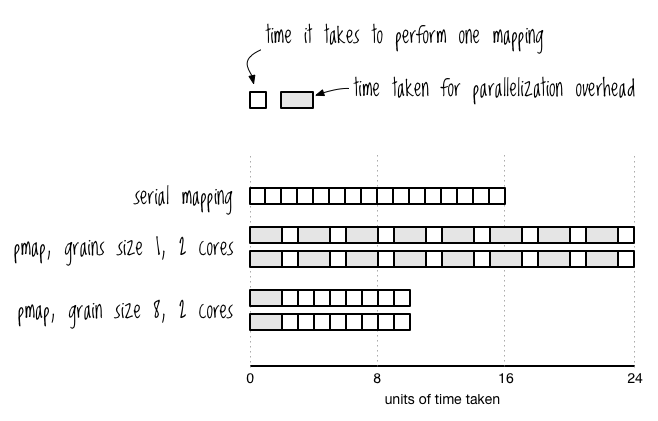
Figure 10-4: Visualizing grain size in relation to parallelization overhead
To actually accomplish this in Clojure, you can increase the grain size by making each thread apply clojure.string/lower-case to multiple elements instead of just one, using partition-all. partition-all takes a seq and divides it into seqs of the specified length:
(def numbers [1 2 3 4 5 6 7 8 9 10])
(partition-all 3 numbers)
; => ((1 2 3) (4 5 6) (7 8 9) (10))
Now suppose you started out with code that looked like this:
(pmap inc numbers)
In this case, the grain size is one because each thread applies inc to an element.
Now suppose you changed the code to this:
(pmap (fn [number-group] (doall (map inc number-group)))
(partition-all 3 numbers))
; => ((2 3 4) (5 6 7) (8 9 10) (11))
There are a few things going on here. First, you’ve now increased the grain size to three because each thread now executes three applications of the inc function instead of one. Second, notice that you have to call doall within the mapping function. This forces the lazy sequence returned by (map inc number-group) to be realized within the thread. Third, we need to ungroup the result. Here’s how we can do that:
(apply concat
(pmap (fn [number-group] (doall (map inc number-group)))
(partition-all 3 numbers)))
Using this technique, we can increase the grain size of the orc name lowercase-ification so each thread runs clojure.string/lower-case on 1,000 names instead of just one:
(time
(dorun
(apply concat
(pmap (fn [name] (doall (map clojure.string/lower-case name)))
(partition-all 1000 orc-name-abbrevs)))))
; => "Elapsed time: 44.677 msecs"
Once again the parallel version takes nearly half the time. Just for fun, we can generalize this technique into a function called ppmap, for partitioned pmap. It can receive more than one collection, just like map:
(defn ppmap
"Partitioned pmap, for grouping map ops together to make parallel
overhead worthwhile"
[grain-size f & colls]
(apply concat
(apply pmap
(fn [& pgroups] (doall (apply map f pgroups)))
(map (partial partition-all grain-size) colls))))
(time (dorun (ppmap 1000 clojure.string/lower-case orc-name-abbrevs)))
; => "Elapsed time: 44.902 msecs"
I don’t know about you, but I think this stuff is just fun. For even more fun, check out the clojure.core.reducers library (http://clojure.org/reducers/). This library provides alternative implementations of seq functions like map and reduce that are usually speedier than their cousins in clojure.core. The trade-off is that they’re not lazy. Overall, the clojure.core.reducers library offers a more refined and composable way of creating and using functions like ppmap.
Summary
In this chapter, you learned more than most people know about safely handling concurrent tasks. You learned about the metaphysics that underlies Clojure’s reference types. In Clojure metaphysics, state is the value of an identity at a point in time, and identity is a handy way to refer to a succession of values produced by some process. Values are atomic in the same way numbers are atomic. They’re immutable, and this makes them safe to work with concurrently; you don’t have to worry about other threads changing them while you’re using them.
The atom reference type allows you to create an identity that you can safely update to refer to new values using swap! and reset!. The ref reference type is handy when you want to update more than one identity using transaction semantics, and you update it with alter! and commute!.
Additionally, you learned how to increase performance by performing stateless data transformations with pmap and the core.reducers library. Woohoo!
Exercises
- Create an atom with the initial value 0, use
swap!to increment it a couple of times, and then dereference it. - Create a function that uses futures to parallelize the task of downloading random quotes fromhttp://www.braveclojure.com/random-quote using
(slurp "http://www.braveclojure.com/random-quote"). The futures should update an atom that refers to a total word count for all quotes. The function will take the number of quotes to download as an argument and return the atom’s final value. Keep in mind that you’ll need to ensure that all futures have finished before returning the atom’s final value. Here’s how you would call it and an example result:(quote-word-count 5) ; => {"ochre" 8, "smoothie" 2} - Create representations of two characters in a game. The first character has 15 hit points out of a total of 40. The second character has a healing potion in his inventory. Use refs and transactions to model the consumption of the healing potion and the first character healing.
 The print book longs for you to own it
The print book longs for you to own it
 OMG what!? Another book!?
OMG what!? Another book!? Great mama of the bahamas! Learn about reducers!
Great mama of the bahamas! Learn about reducers!